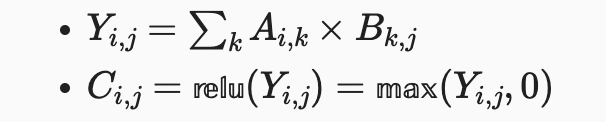The RISC-V Vector Extension (RVV) has been ratified lately and new to the world. It is a VLA (Vector Length Agnostic) vector extension and its behavior relies on the setting of vtype register. Two of the fields, vta and vma, determines the behaviors for tail elements and inactive elements respectively.
Definition of the extension is established by the riscv-v-spec. Even though the spec gives me a good top-down overview of the extension, several instructions behave differently than the generic behavior. This sometime leaves me confused and slow down my development.
This article wants to gather information regarding the policy configuration for RVV and hope to help people understand more of RVV.
The “agnostic” behavior
When a set is marked agnostic, the corresponding set of destination elements in any vector destination operand can either retain the value they previously held, or are overwritten with 1s. Within a single vector instruction, each destination element can be either left undisturbed or overwritten with 1s, in any combination, and the pattern of undisturbed or overwritten with 1s is not required to be deterministic when the instruction is executed with the same inputs.
risc-v v-spec
Tail policy behavior
Remaining spaces of destination register are treated as tail elements
Fractional LMUL may occur on generic vector instructions. In this case, the rest of the vector space is treated as tail elements and respects vta setting.
For vector segment instructions, since EMUL = (EEW / SEW) * LMUL, we may obtain fractional EMUL and the rest of the vector space is treated as tail elements and respects vta setting.
Instructions with mask destination registers are always tail-agnostic
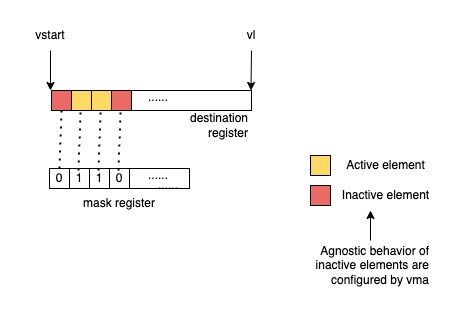
Be noted of how the v-spec stated about the mask register layout:
Each element is allocated a single mask bit in a mask vector register. The mask bit for element i is located in bit i of the mask register, independent of SEW or LMUL.
Regarding an instruction that has a mask destination register, the tail elements ranges from the vl-th bit to the VLEN-1-th bit.
Store instructions are not affected by policy settings
The destination of store instructions is the memory. No vector register is involved, therefore the policy settings don’t affect them.
Mask policy behavior
Unmasked instructions don’t care about mask policy
Some instructions are always unmasked, meaning that the instructions have no inactive elements. They are not affected by mask policy.
- Vector add-with-carry and subtract-with-borrow instructions
- Vector merge and move instructions
- Vector mask-register logical instructions
vcompress
Reduction instructions don’t care about mask policy
Additionally, vector reduction instructions don’t care about mask policy too because the inactive elements are excluded from reduction. The 0th element of the destination register will hold the result of the reduction and other elements in the destination vector register will respect the tail policy.
Ending
Hope this post saved someone’s time in the world from tangling details of RVV policies 😉