中文譯名:原罪犯(譯名不要想劇透人好嗎)
The Last Waltz 好好聽⋯⋯
Author: eopXD
Hi 我是 eopXD ,希望人生過得有趣有挑戰。
2023 LLVM Dev Mtg NA: How to add an C intrinsic and code-gen it, using the RISC-V vector C intrinsics
基本上把這一年半以來,把 RISC-V Vector Intrinsics 從初始的版本完善到現在接近對 RISC-V Vector Extension v1.0 的 functional completeness 所進行的軟體工程做技術介紹。
希望可以對後繼 LLVM 其他 back-end 的開發者有幫助~
回想起來,非常感謝 Kito Cheng 密集地與我技術討論,Craig Topper 與 Roger Ferrer Ibanez 的 code review,還有 Nick Knight 一針見血的反饋與改進方案。
生きる (1952)
中文譯名:生之慾
同場加應:〈生きる〉。谷川 俊太郎
Le Procès Goldman (2023)
英文譯名:The Goldman Case
中文譯名:罪後辯護
2022 RISC-V Summit: Spike Usage and Adding V Extension Support to Spike
這次很高興被 PLCT 的 Wei Wu 邀請,可以去加州在 RISC-V Summit 上幫忙介紹 Spike 這個從 SiFive 創辦之初在 Berkeley 實驗室中開發出來的 Simulator。
希望這個介紹可以幫助人們了解 Spike 還有 RISC-V Vector Extension。
2022 LLVM Dev Mtg, San Jose
我總覺得開源是一種信仰。在一個想像的共同體下大家用自己的雙手把這個共同體不斷變得更好。編譯器這麼博大精深,除了會碰到的東西之外,這場會議讓我有機會看到大家正在 LLVM 這個巨大的 mono-repo 底下正在做什麼樣的 project 和努力,某些時刻真的是倍感溫馨。
Continue reading “2022 LLVM Dev Mtg, San Jose”MLC quick notes – Week 4
過去兩週解釋了對 Tensor Primitive Function 的實作可能。這週退一步來看,給出了如何抵達要去實作 primitive function 的 high level workflow overview。
Continue reading “MLC quick notes – Week 4”MLC quick notes – Week 3
這週用 TVM 中的 TensorIR 來實際展示 Tensor Computation 的必要元素——如何從較粗糙的 ML Operator 轉換成可以實際編譯執行(Deployable)的 Primitive Function。
課程中舉例。現在 ML Model 是簡單的矩陣相乘(Matrix Multiplication)之後接一個整流函數(ReLU)。表示成數學式為:
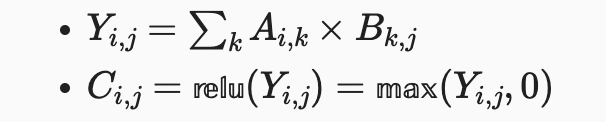
這裡 TQ 直接切入 Python abstraction 底下,開始介紹 TVM 所提供的 API — axis_type, axis_range and mapped_value。並且展示了 TVM 提供 Loop Splitting, Loop Interchange 的 API 來做出 Tiling 的例子。
不過大家真正想學的應該也不是 TVM,整場聽你安麗就飽了啊 (☉д⊙)(?)。這裡的 take-away 應該是我們需要解決的問題——在高階語言後關心實際實作(如何分配 multithreading)與執行(環境下的 locality)的最佳化。
在課程中 TQ 用 TVM 所示範的 Tiling 例子,其實追根究底是複用了 Halide [1] 的最核心概念—— Decoupling Algorithm from Schedules [2]。 TVM 所展現的 modularity 就是透過這樣的 decoupling 產生的。經過解耦,可以展開出 multithreading 與 locality 的解平面來做最佳化。ML operator 的確也是這一概念很好的應用對象!
個人 OS:要是乖乖上課不查資料就真的只是 TVM 新生訓練而已了⋯⋯
[1] Halide: A Language and Compiler for Optimizing Parallelism, Locality, and Recomputation in Image Processing Pipelines
[2] Decoupling Algorithms from Schedules for Easy Optimization of Image Processing Pipelines
RVV vector elements and its policy behaviors
The RISC-V Vector Extension (RVV) has been ratified lately and new to the world. It is a VLA (Vector Length Agnostic) vector extension and its behavior relies on the setting of vtype register. Two of the fields, vta and vma, determines the behaviors for tail elements and inactive elements respectively.
Definition of the extension is established by the riscv-v-spec. Even though the spec gives me a good top-down overview of the extension, several instructions behave differently than the generic behavior. This sometime leaves me confused and slow down my development.
This article wants to gather information regarding the policy configuration for RVV and hope to help people understand more of RVV.
The “agnostic” behavior
When a set is marked agnostic, the corresponding set of destination elements in any vector destination operand can either retain the value they previously held, or are overwritten with 1s. Within a single vector instruction, each destination element can be either left undisturbed or overwritten with 1s, in any combination, and the pattern of undisturbed or overwritten with 1s is not required to be deterministic when the instruction is executed with the same inputs.
risc-v v-spec
Tail policy behavior

Remaining spaces of destination register are treated as tail elements
Fractional LMUL may occur on generic vector instructions. In this case, the rest of the vector space is treated as tail elements and respects vta setting.
For vector segment instructions, since EMUL = (EEW / SEW) * LMUL, we may obtain fractional EMUL and the rest of the vector space is treated as tail elements and respects vta setting.
Instructions with mask destination registers are always tail-agnostic
Be noted of how the v-spec stated about the mask register layout:
Each element is allocated a single mask bit in a mask vector register. The mask bit for element i is located in bit i of the mask register, independent of SEW or LMUL.
Regarding an instruction that has a mask destination register, the tail elements ranges from the vl-th bit to the VLEN-1-th bit.
Store instructions are not affected by policy settings
The destination of store instructions is the memory. No vector register is involved, therefore the policy settings don’t affect them.
Mask policy behavior
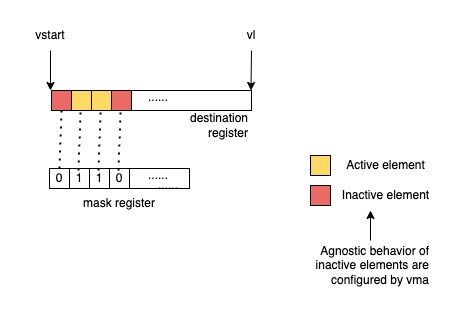
Unmasked instructions don’t care about mask policy
Some instructions are always unmasked, meaning that the instructions have no inactive elements. They are not affected by mask policy.
- Vector add-with-carry and subtract-with-borrow instructions
- Vector merge and move instructions
- Vector mask-register logical instructions
vcompress
Reduction instructions don’t care about mask policy
Additionally, vector reduction instructions don’t care about mask policy too because the inactive elements are excluded from reduction. The 0th element of the destination register will hold the result of the reduction and other elements in the destination vector register will respect the tail policy.
Ending
Hope this post saved someone’s time in the world from tangling details of RVV policies 😉
MLC quick notes – Week 2
本週進一步探討了在機器學習模型這樣的問題框架下,抽象化的表示至少需要哪些。最直觀來說是 Input / Output buffer representations (placeholders), Loop nests and Computation statements.
Primitive tensor function 就是在模型上最直接的那些 operator,諸如 linear, relu, softmax。而要編譯這些 operator:
- 一種最簡單的方式就是硬體都幫你做好好,直接切處這樣 coarse grain 的 API,model 來哪種 operator 就直接送給硬體做
- 更 fine grain 來說,對 operator 執行的程式碼(迴圈)做優化
最直接的例子,就是從大家最熟悉的 SIMD programming scheme 開始。像是 NEON 或是 AVX512 都可以作為實際例子。而從一個簡單的 for loop 要轉成較適用 SIMD 的程式,需要 Loop Splitting:
// From
for (int i=0; i<128; ++i) {
c[i] = a[i] + b[i];
}
// To (Exploit parallelism with SIMD
for (int i=0; i<32; ++i) {
for (int j=0; j<4; ++j) { // deal with 4 computations at a time
c[i * 4 + j] = a[i * 4 + j] + b[i * 4 + j];
}
}
更甚至需要 core 上的平行話時,可以 Loop Interchange 成:
// To (Exploit parallelism through multiple cores
for (int j=0; j<4; ++j) { // 4 cores
for (int i=0; i<32; ++i) {
c[i * 4 + j] = a[i * 4 + j] + b[i * 4 + j];
}
}
這樣的 transformation,加上需要轉換到 CUDA 上的話,在抽象化來講可以寫成以下這樣:
// From p.16 of <https://mlc.ai/summer22/slides/2-TensorProgram.pdf>
x = get_loop("x")
xo, xi = split(x, 4)
reorder(xi, xo)
bind_thread(xo, "threadIdx.x")
bind_thread(xi, "blockIdx.x")
在 compiler 來說,對於各式各樣的 loop 當然是希望能夠被提供越多資訊越好,諸如 IBM / Intel 都有一些自家 pragma,在 ML 領域內我們也希望能夠被提供這樣的資訊,像是「有沒有 loop carried dependency」或是直接像 p.18 裡直接指名該 tensor 所有元素是 spatially parallelize-able。
總的來說,這週展示了 operator 底下的優化空間。
最後 20 分鐘就是講師在安立自家的 TVM XD
額外 brain storming:MLIR 跟 TVM 都幾?難道又像古時候的編譯器一樣,ML compilation 是否也要進入戰國時代了呢?
